Getting Data from the Web
You’ve tried everything else, and you haven’t managed to get your hands on the data you want. You’ve found the data on the web, but, alas — no download options are available and copy-paste has failed you. Fear not, there may still be a way to get the data out. For example you can:
-
Get data from web-based APIs, such as interfaces provided by online databases and many modern web applications (including Twitter, Facebook and many others). This is a fantastic way to access government or commercial data, as well as data from social media sites.
-
Extract data from PDFs. This is very difficult, as PDF is a language for printers and does not retain much information on the structure of the data that is displayed within a document. Extracting information from PDFs is beyond the scope of this book, but there are some tools and tutorials that may help you do it.
-
Screen scrape web sites. During screen scraping, you’re extracting structured content from a normal web page with the help of a scraping utility or by writing a small piece of code. While this method is very powerful and can be used in many places, it requires a bit of understanding about how the web works.
With all those great technical options, don’t forget the simple options: often it is worth to spend some time searching for a file with machine-readable data or to call the institution which is holding the data you want.
In this chapter we walk through a very basic example of scraping data from an HTML web page.
What is machine-readable data?
The goal for most of these methods is to get access to machine-readable data. Machine readable data is created for processing by a computer, instead of the presentation to a human user. The structure of such data relates to contained information, and not the way it is displayed eventually. Examples of easily machine-readable formats include CSV, XML, JSON and Excel files, while formats like Word documents, HTML pages and PDF files are more concerned with the visual layout of the information. PDF for example is a language which talks directly to your printer, it’s concerned with position of lines and dots on a page, rather than distinguishable characters.
Scraping web sites: what for?
Everyone has done this: you go to a web site, see an interesting table and try to copy it over to Excel so you can add some numbers up or store it for later. Yet this often does not really work, or the information you want is spread across a large number of web sites. Copying by hand can quickly become very tedious, so it makes sense to use a bit of code to do it.
The advantage of scraping is that you can do it with virtually any web site — from weather forecasts to government spending, even if that site does not have an API for raw data access.
What you can and cannot scrape
There are, of course, limits to what can be scraped. Some factors that make it harder to scrape a site include:
-
Badly formatted HTML code with little or no structural information e.g. older government websites.
-
Authentication systems that are supposed to prevent automatic access e.g. CAPTCHA codes and paywalls.
-
Session-based systems that use browser cookies to keep track of what the user has been doing.
-
A lack of complete item listings and possibilities for wildcard search.
-
Blocking of bulk access by the server administrators.
Another set of limitations are legal barriers: some countries recognize database rights, which may limit your right to re-use information that has been published online. Sometimes, you can choose to ignore the license and do it anyway — depending on your jurisdiction, you may have special rights as a journalist. Scraping freely available Government data should be fine, but you may wish to double check before you publish. Commercial organizations — and certain NGOs — react with less tolerance and may try to claim that you’re “sabotaging” their systems. Other information may infringe the privacy of individuals and thereby violate data privacy laws or professional ethics.
Tools that help you scrape
There are many programs that can be used to extract bulk information from a web site, including browser extensions and some web services. Depending on your browser, tools like Readability (which helps extract text from a page) or DownThemAll (which allows you to download many files at once) will help you automate some tedious tasks, while Chrome’s Scraper extension was explicitly built to extract tables from web sites. Developer extensions like FireBug (for Firefox, the same thing is already included in Chrome, Safari and IE) let you track exactly how a web site is structured and what communications happen between your browser and the server.
ScraperWiki is a web site that allows you to code scrapers in a number of different programming languages, including Python, Ruby and PHP. If you want to get started with scraping without the hassle of setting up a programming environment on your computer, this is the way to go. Other web services, such as Google Spreadsheets and Yahoo! Pipes also allow you to perform some extraction from other web sites.
How does a web scraper work?
Web scrapers are usually small pieces of code written in a programming language such as Python, Ruby or PHP. Choosing the right language is largely a question of which community you have access to: if there is someone in your newsroom or city already working with one of these languages, then it makes sense to adopt the same language.
While some of the click-and-point scraping tools mentioned before may be helpful to get started, the real complexity involved in scraping a web site is in addressing the right pages and the right elements within these pages to extract the desired information. These tasks aren’t about programming, but understanding the structure of the web site and database.
When displaying a web site, your browser will almost always make use of two technologies: HTTP is a way for it to communicate with the server and to request specific resource, such as documents, images or videos. HTML is the language in which web sites are composed.
The anatomy of a web page
Any HTML page is structured as a hierarchy of boxes (which are defined by HTML “tags”). A large box will contain many smaller ones — for example a table that has many smaller divisions: rows and cells. There are many types of tags that perform different functions — some produce boxes, others tables, images or links. Tags can also have additional properties (e.g. they can be unique identifiers) and can belong to groups called ‘classes’, which makes it possible to target and capture individual elements within a document. Selecting the appropriate elements this way and extracting their content is the key to writing a scraper.
Viewing the elements in a web page: everything can be broken up into boxes within boxes.
To scrape web pages, you’ll need to learn a bit about the different types of elements that can be in an HTML document. For example, the <table> element wraps a whole table, which has <tr> (table row) elements for its rows, which in turn contain <td> (table data) for each cell. The most common element type you will encounter is <div>, which can basically mean any block of content. The easiest way to get a feel for these elements is by using the developer toolbar in your browser: they will allow you to hover over any part of a web page and see what the underlying code is.
Tags work like book ends, marking the start and the end of a unit. For example <em> signifies the start of an italicized or emphasized piece of text and </em> signifies the end of that section. Easy.
An example: scraping nuclear incidents with Python
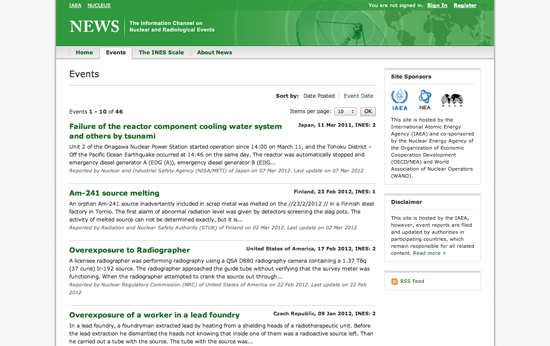
NEWS is the International Atomic Energy Agency’s (IAEA) portal on world-wide radiation incidents (and a strong contender for membership in the Weird Title Club!). The web page lists incidents in a simple, blog-like site that can be easily scraped.
To start, create a new Python scraper on ScraperWiki and you will be presented with a text area that is mostly empty, except for some scaffolding code. In another browser window, open the IAEA site and open the developer toolbar in your browser. In the “Elements” view, try to find the HTML element for one of the news item titles. Your browser’s developer toolbar helps you connect elements on the web page with the underlying HTML code.
Investigating this page will reveal that the titles are <h4> elements within a <table>. Each event is a <tr> row, which also contains a description and a date. If we want to extract the titles of all events, we should find a way to select each row in the table sequentially, while fetching all the text within the title elements.
In order to turn this process into code, we need to make ourselves aware of all the steps involved. To get a feeling for the kind of steps required, let’s play a simple game: In your ScraperWiki window, try to write up individual instructions for yourself, for each thing you are going to do while writing this scraper, like steps in a recipe (prefix each line with a hash sign to tell Python that this not real computer code). For example:
Try to be as precise as you can and don’t assume that the program knows anything about the page you’re attempting to scrape.
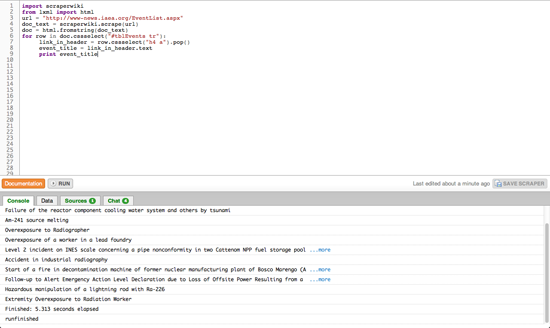
Once you’ve written down some pseudo-code, let’s compare this to the essential code for our first scraper:
In this first section, we’re importing existing functionality from libraries — snippets of pre-written code. scraperwiki will give us the ability to download web sites, while lxml is a tool for the structured analysis of HTML documents. Good news: if you are writing a Python scraper with ScraperWiki, these two lines will always be the same.
Next, the code makes a name (variable): url, and assigns the URL of the IAEA page as its value. This tells the scraper that this thing exists and we want to pay attention to it. Note that the URL itself is in quotes as it is not part of the program code but a string, a sequence of characters.
We then use the url variable as input to a function, scraperwiki.scrape. A function will provide some defined job — in this case it’ll download a web page. When it’s finished, it’ll assign its output to another variable, doc_text. doc_text will now hold the actual text of the website — not the visual form you see in your browser, but the source code, including all the tags. Since this form is not very easy to parse, we’ll use another function, html.fromstring, to generate a special representation where we can easily address elements, the so-called document object model (DOM).
In this final step, we use the DOM to find each row in our table and extract the event’s title from its header. Two new concepts are used: the for loop and element selection (.cssselect). The for loop essentially does what its name implies; it will traverse a list of items, assigning each a temporary alias (row in this case) and then run any indented instructions for each item.
The other new concept, element selection, is making use of a special language to find elements in the document. CSS selectors are normally used to add layout information to HTML elements and can be used to precisely pick an element out of a page. In this case (Line. 6) we’re selecting #tblEvents tr which will match each <tr> within the table element with the ID tblEvents (the hash simply signifies ID). Note that this will return a list of <tr> elements.
As can be seen on the next line (Line. 7), where we’re applying another selector to find any <a> (which is a hyperlink) within a <h4> (a title). Here we only want to look at a single element (there’s just one title per row), so we have to pop it off the top of the list returned by our selector with the .pop() function.
Note that some elements in the DOM contain actual text, i.e. text that is not part of any markup language, which we can access using the [element].text syntax seen on line 8. Finally, in line 9, we’re printing that text to the ScraperWiki console. If you hit run in your scraper, the smaller window should now start listing the event’s names from the IAEA web site.
You can now see a basic scraper operating: it downloads the web page, transforms it into the DOM form and then allows you to pick and extract certain content. Given this skeleton, you can try and solve some of the remaining problems using the ScraperWiki and Python documentation:
-
Can you find the address for the link in each event’s title?
-
Can you select the small box that contains the date and place by using its CSS class name and extract the element’s text?
-
ScraperWiki offers a small database to each scraper so you can store the results; copy the relevant example from their docs and adapt it so it will save the event titles, links and dates.
-
The event list has many pages; can you scrape multiple pages to get historic events as well?
As you’re trying to solve these challenges, have a look around ScraperWiki: there are many useful examples in the existing scrapers — and quite often, the data is pretty exciting, too. This way, you don’t need to start off your scraper from scratch: just choose one that is similar, fork it and adapt to your problem.
